

Flink集群部署手册(Standalone运行模式)
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
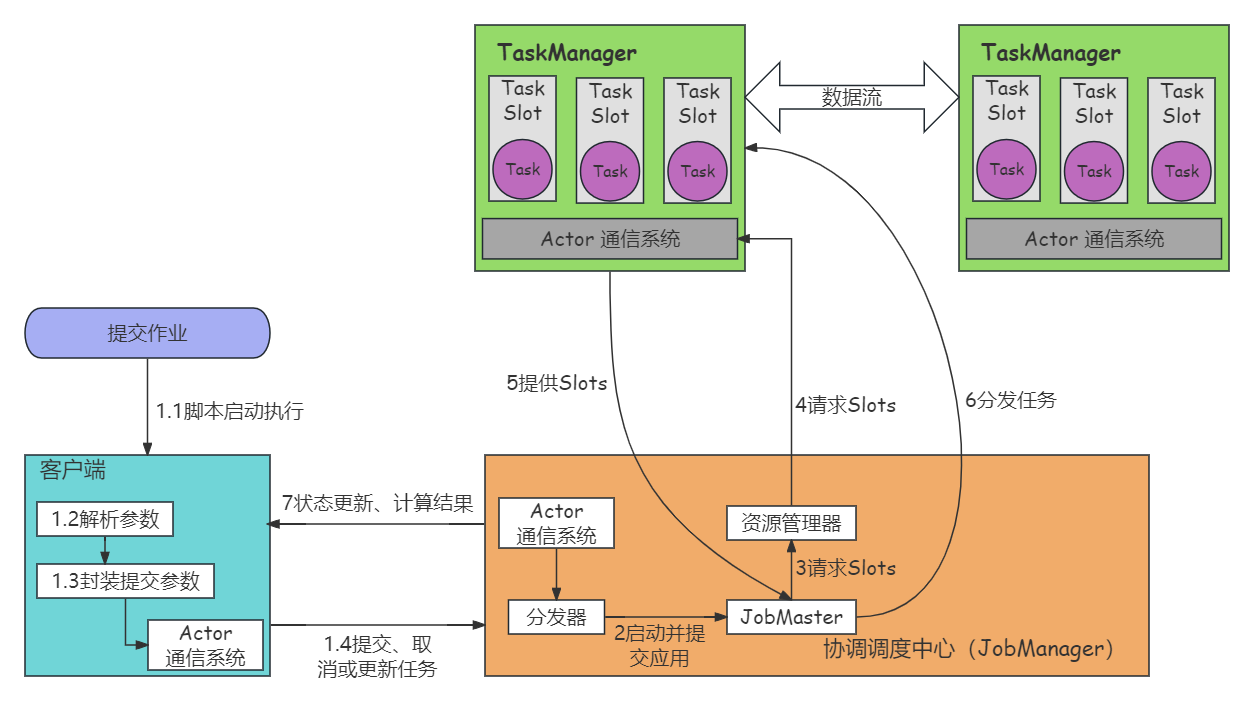
Flink运行架构
一、环境准备
Flink下载
Flink下载地址
按照flink-1.17.1 下载Flink
安装java环境
三、解压flink
四、修改配置文件
本项修改均在flink目录/flink-1.17.1/conf/的flink-conf.yaml文件中进行
1、修改JobManager节点地址
| 修改项 | 修改值 |
|---|---|
| jobmanager.rpc.address | 值修改为第一台服务器地址,地址是设置master |
| jobmanager.bind-host | 值修改为 0.0.0.0 |
| rest.address | 值修改为master的服务器地址 |
| rest.bind-address | 值修改为 0.0.0.0 |
2、修改TaskManager节点地址
| 修改项 | 修改值 |
|---|---|
| taskmanager.bind-host | 值修改为 0.0.0.0 |
| taskmanager.host | 值修改为当前节点服务器IP |
3、JobManager和TaskManager组件优化配置
| 修改项 | 修改项说明 |
|---|---|
| jobmanager.memory.process.size | 对JobManager进程可使用到的全部内存进行配置, 包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。 |
| taskmanager.memory.process.size | 对TaskManager进程可使用到的全部内存进行配置, 包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。 |
| taskmanager.numberOfTaskSlots | 对每个TaskManager能够分配的Slot数量进行配置, 默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。 |
| parallelism.default | Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。 |
五、分配节点
1、分配master节点
进入flink目录/flink-1.17.1/conf/目录修改master文件
将master内容修改为master节点IP+8081端口
2、分配work节点
进入flink目录/flink-1.17.1/conf/目录修改work文件
将work内容修改为work节点IP,每个IP回车隔离
六、启动\停止Flink集群
启动
在第一台服务器(master节点)进入flink目录/flink-1.11.1/bin执行start-cluster.sh
停止
在第一台服务器(master节点)进入flink目录/flink-1.11.1/bin执行stop-cluster.sh
七、访问
查看Flink Web UI界面,访问master地址+8081端口
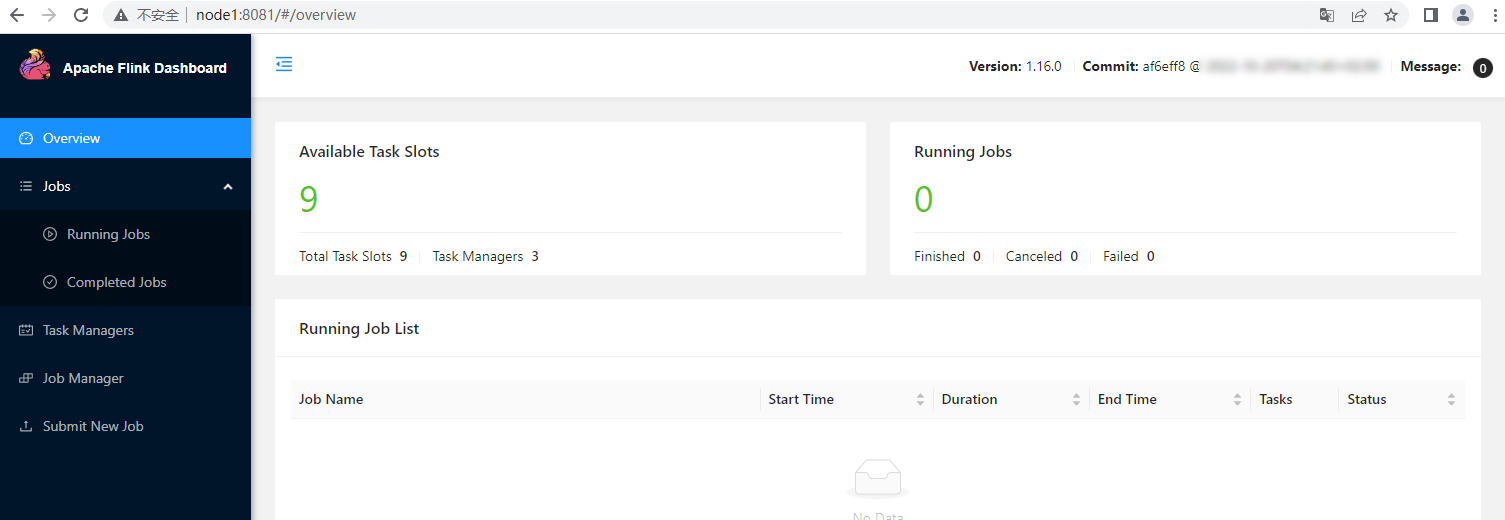
注意:集群中Available Task Slots数量是所有work节点中

评论